LLM은 모르지만 뭔가 만들고 싶어서
인지적 프롬프팅으로 3시간 만에 기능 만들어본 이야기

AI. 정확히는 LLM을 통해 만들어보고 싶은 것이 생겼다.
에어브릿지에는 마케팅 성과를 실시간으로 확인할 수 있는 리포트가 있는데, 보다 세밀한 데이터를 보려면 설정할 것이 많아 적응에 시간이 조금 걸린다. 이걸 ‘이번 달에 인스타그램으로 유입된 사람들이 나이키 신발을 얼마나 구매했어?’처럼 물어볼 수 있게 바꾸면 재밌을 것 같았다.
하지만 큰 문제가 있었다. 내가 LLM을 잘 모른다는 것이었다.
그야 리포트 API 스펙 문서를 넣고 질문해도 동작은 하겠지만, 혼자 쓰는 것이 아니라 기능으로 만들고 싶다면, 답변의 정확도가 높아야 사용자의 신뢰를 얻을 수 있다.
모르는 게 많았지만 ‘인지적 프롬프팅(Cognitive Prompting)’ 자료를 보고 써먹어보면서 3시간 만에 기능을 만들 수 있었다. 그때 느낀 점을 짧게나마 기록해두려고 한다.
LLM을 다루는 두 가지 그림
인지적 프롬프팅을 생각하며 나는 LLM을 다루는 일을 크게 두 가지 그림으로 생각하게 되었다.
순서와 위계를 만들어야하고(Sequential), 여러 갈래로 지식을 수집한 뒤 하나로 잘 합쳐야 한다(Collective). 했던 일을 돌아보며 하나씩 뜯어보자.
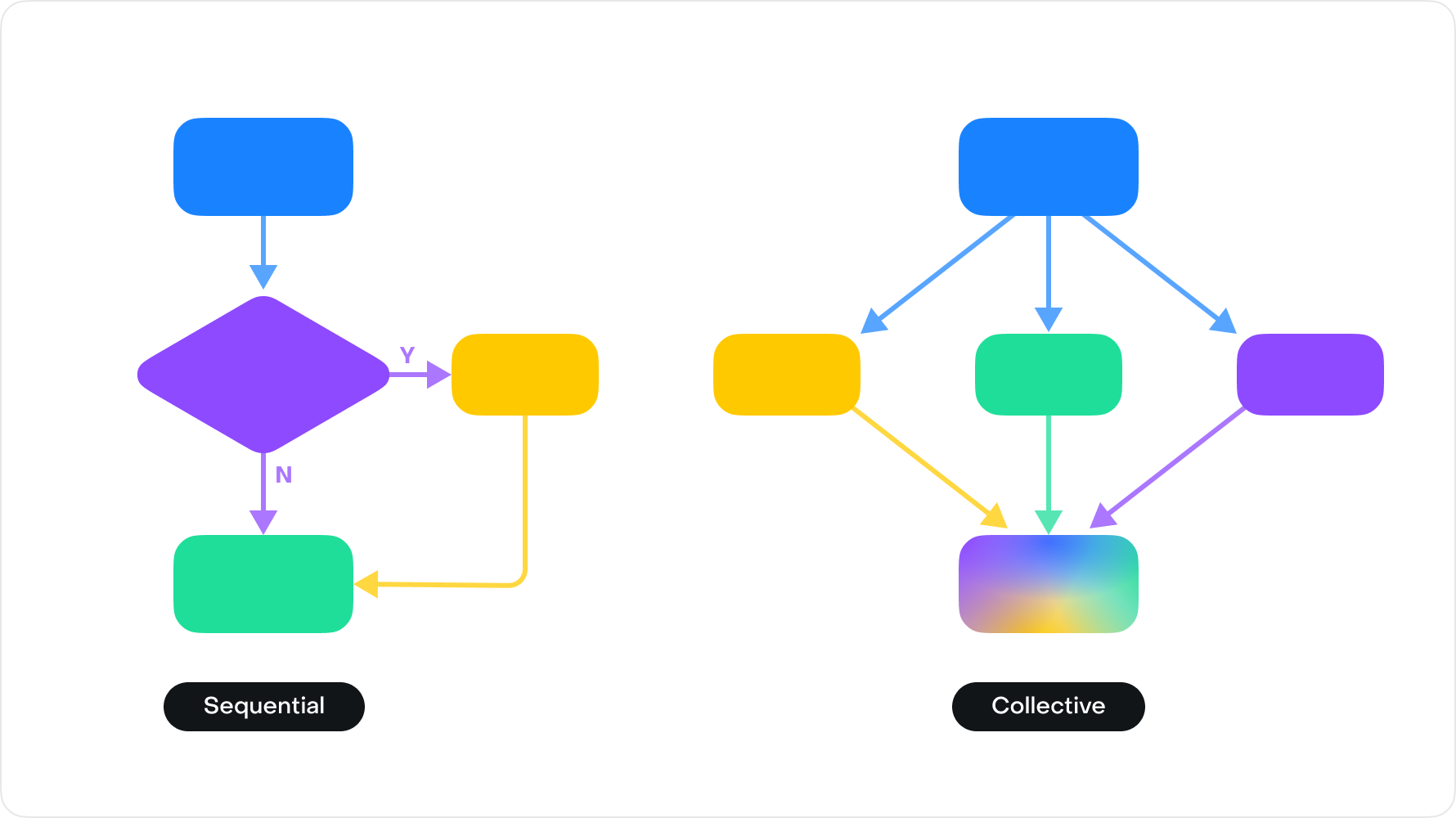
Sequential, 일에는 순서가 있다
일단 리포트를 어떻게 설정하면 되는지 떠올리며 작업을 작게 나누었다. 요구사항을 읽고 지표와 그룹바이, 필터, 기간 등을 설정한다.
이걸 빼먹으면 원하는 결과를 못 얻는 판단, 내가 익숙하게 하고 있던 행동도 찾아본다. 데이터 스펙의 설명을 읽고 데이터 예시를 확인해 지표를 선택하는 것, 오가닉(Organic, 순수 유입) 유저에 관한 내용이면 필터로 일부 매체를 제외시키는 것이 떠올랐다.
그것들이 모두 끝난 뒤 중요도에 따라 순서를 매겨 세워보니 리포트 API 스펙 문서에 아쉬운 점이 보였다. 보다 순서와 위계가 잘 드러나면 좋겠다고 생각하여 새로 작성하기로 했다.
누군가에게 작업을 맡길 때를 생각해보자. 일의 크기가 작을수록, 순서와 위계가 명확할수록, 결과(혹은 기대효과)가 확실할수록 맡긴 일의 퀄리티가 좋다. 이를 LLM에도 똑같이 적용할 수 있을까?
같은 문서 혹은 지식이라도 PDF보다 웹문서(XML) 혹은 마크다운(Markdown)으로 준다면 더 좋은 결과를 얻을 수 있겠다고 생각했다. XML은 탭과 태그를 사용해 위계를 나타내거나 그룹을 묶을 수 있고, 마크다운은 헤딩, 볼드 같은 서식을 활용해 위계를 나타낼 수 있다.
그래서 마크다운을 사용하되 순서를 잘 표현하기 위해 헤딩 앞에 1.3. 과 같이 순서를 매겼다.
Collective, 전문가의 전문가
인지적 프롬프팅의 자료를 보며 두 가지 내용이 인상깊었다:
-
LLM은 새로운 것을 만들어내는 것이 아니다. 다만 **‘빈칸 채우기’**처럼 문맥을 읽고 그 뒤에 나올법한 이야기를 하는 것뿐이다.
-
LLM은 전세계 수많은 웹페이지들을 학습했다. 그렇다면 **‘모든 것의 전문가’**로 생각하며 적절한 질문을 통해 전문성을 끌어낼 수도 있다.
이를 프롬프트에 최대한 써먹어보려고 했다. 단순하게는 ‘당신은 API 가이드를 읽고 사람들의 요구사항을 잘 반영하는 전문가’라는 문장을 넣었다. 조금 더 나아가서는 ‘이 분야의 여러 전문가들에게 물어봐서 정보를 얻은 뒤에 하나로 취합해서 내게 알려달라’고 하는 것까지.
프롬프트를 개선하면서 어떤 단어를 쓰는지도 큰 영향을 준다는 것을 알았다.
만약 규칙이 반드시 지켜져야할 때, ensure보다 일상 표현인 must를 쓰는 것이 좋았다. 전문성이 들어가는 작업을 한다면, 업계에서 많이 쓰는 단어를 넣는 것이 좋다. 이번에는 Conversion이나 Retention, CPI, CPC 같은 단어를 프롬프트에 넣었다.
**keep these things or you'll be fired:**먼저 돌아가게, 그 다음 튜닝하기
LLM 모델을 찾아보니 뭐가 많았다. 같은 모델도 급에 따라 성능과 비용이 많이 달랐다. 만약 기능으로 제공하고 싶다면 비용도 저렴하며 응답 속도 역시 빨라야한다.
하지만 첫 술에 배부를 수는 없다. 가장 좋은 모델에서 시작해서 점진적으로 난이도를 높여가기로(모델 낮추기, 프롬프트 튜닝 등) 했다. 새로 나왔던 Claude-3의 Opus를 시작으로 Sonnet까지 내리며 그때그때 보이는 문제를 수정했다.
모델을 낮춘 뒤에 시스템 프롬프트로 넘기는 토큰의 수를 줄였다. 토큰=단어라고 단순하게 생각해서 처음에는 문장을 정리하는 것만 했다. 그런데 알고 보니, 마크다운의 테이블 헤더를 표현하는 | --- | 표시를 좀 줄였더니 토큰이 절반 정도 줄어들었다.
1시간 정도 이 과정을 거쳤고, 비용만 비교했을 때 처음 대비 1/50의 비용으로 만들 수 있었다. 내가 잘 모르는 부분이 많으니 분명 더 최적화할 수 있는 부분이 있을 것이다.
‘Sequential’와 ‘Collective’라는 키워드를 얻어, 일을 작게 쪼개고, 순서와 위계를 만들고, 전문가에게 질문하듯 프롬프트를 만들었다. 그 뒤에는 점진적으로 난이도를 높이며 개선했다.
‘잘 모르는데도 뭔가를 만들어낼 수 있다니!’
이번처럼 불편한 부분을 개선하거나 무언가를 더 잘하게 만드는 데 LLM을 사용해보려고 한다. 이전에는 LLM이 추상적으로 느껴졌는데, 이제는 좀 흥미롭게 느껴진다.
그리고 이번에 만든 것은 리서치 팀에서 더 고도화해주시기로 했다. 단순 리포트 설정을 해주는 것에서 더 나아가 온보딩에 사용할 수 있다는 아이디어가 나왔다. 예를 들어, ‘캐주얼 게임을 운영하고 있는데 내가 보면 좋을 리포트 5개를 만들어줘’ 라고 질문하면, 수익 분석이나 광고 그룹 별 전환율을 확인할 수 있는 리포트 설정을 생성할 수 있다. 서비스 별로 최적화된 온보딩 경험을 줄 수 있는 것이다.
리서치 팀원분과 이야기를 나눠보니 반년 전에 비슷한 시도를 했을 때에는 되지 않았는데, 이게 된다고 하니 놀랐다고 말씀해주셨다. 기술의 발전이 참 빠르다…